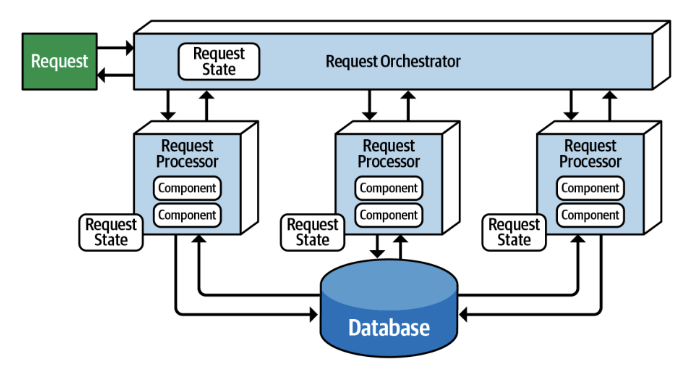
Request-based model
Request (Perform some sort of actions) send to Request Orchestrator
Terminology
- Request Orchestrator: Component that receive request, figure out what to be done, and coordinate the flow
- Example: Web Frontend, API Gateway, Controller of MVC
- Deterministically and Synchronously direct request to request processor
Flow
- You ask system to do something (Customer click button to see order history from past 6 months)
- System follow clear steps to get the return data
- Only work when you ask for it
Event-based Architecture Style
Distributed Asynchronous architecture style that made up of decouple event processing components that asynchronously receive + process events
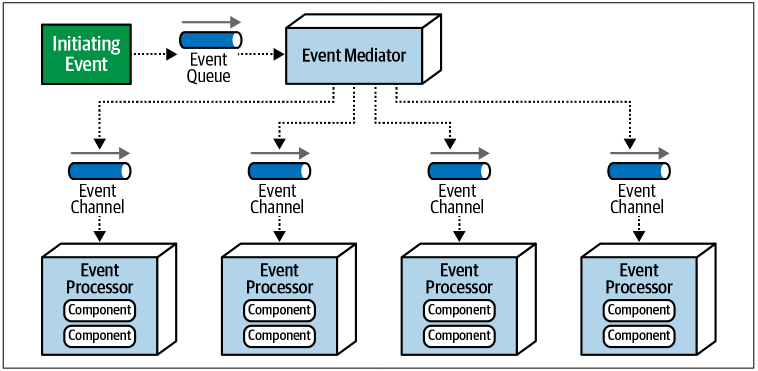
Mediator Topology
Use central mediator to orchestrate and coordinate the event flow across multiple event processors
Components
- Mediator: Central coordinator managing flow of events and responses
- Event Processors: Independent components doing tasks like validation, payment, etc.
- Event Queues/Bus: Communication channel for publishing/subscribing events
Flow (EX: Placing an Order)
- Client trigger a
PlaceOrderevent - Mediator receives the event
- Mediator:
- Sends
ValidateOrderto one processor - Waits for validation
- Sends
ReserveInventoryto another proces11sor - Sends
ChargeCustomerto another - When everything success, send
SendConfirmation
- Sends
- Each processors do their own jobs, may return results - raise errors
- Mediator manages the sequence and error handling
Characteristics
- Best for complex workflow where sequence, logic and coordination are important
Trade-offs
Advantage
- Centralized workflow control
- Easier for handling and rollback
- Good for complex + ordered tasks Disadvantage
- Tight coupling between mediator and processors
- Lower scalability and performance compared to broker
- Single point of failure if not design for high availability
Broker Topology
Remove central orchestrator. Each event processor subscribe to events and acts independently based on event its receives.
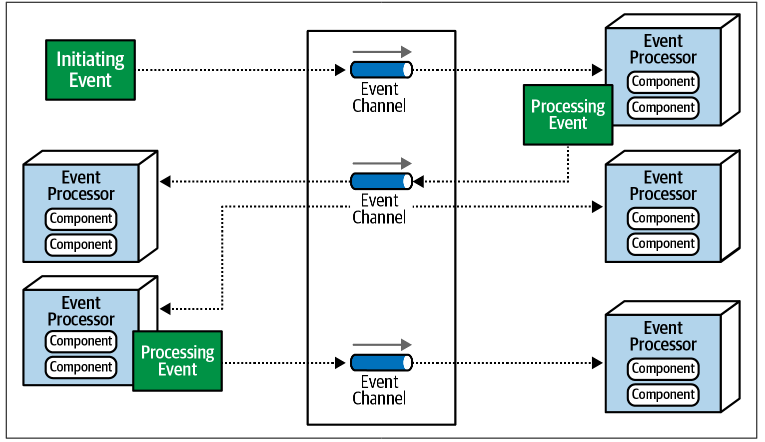
Components
- Event Broker: Message broker (RabbitMQ, Kafka, etc.) that handles event distribution
- Event Processors: Decentralized units that act on events
- Event Queue/Bus: Backbone that connect producer and consumers
Flow (EX: Placing an Order)
- Client publishes a
PlaceOrderevent to event broker - Multiples processors listen for that event:
- One validation the order
- Another reserves inventory
- Another charges the customer
- Another sends the confirmation
- Processors may emit new events (
OrderValidated,InventoryReserved), which will trigger other processor
Characteristic
- Best for high-throughput (Process large volume), need performance, scalability and loose coupling are more important than coordination
Trade-offs
Advantages
- High scalability and performance
- Loose coupling between components
- Resilient and fault-tolerant
Disadvantages
- Harder to manage complex workflow
- More difficult for error handling and rollback
- Less control over event flow and sequencing
Space-Based Architecture Style
- Design to address issues related to high-scalability, elasticity, and concurrency
- Help solve problem of database bottlenecks which often encounter in traditional web app flow (browser → web server → application server → database server)
- It remove central database → Use replicated in-memory data grids allow near-infinite scalability
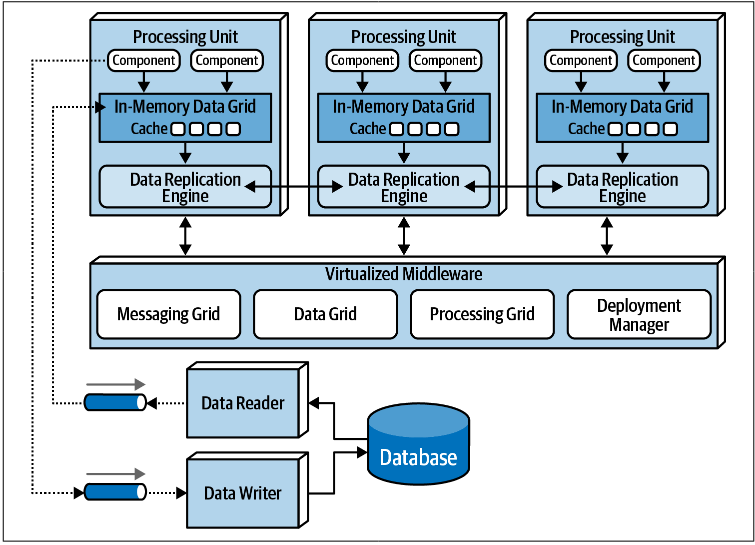
Components
Processing Units
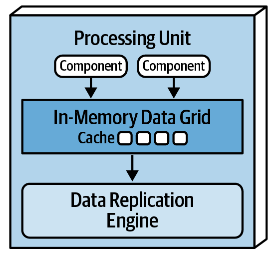
- Contain application logic (Portions or Entire application, including web component + backend logic)
- Larger application split functionality into multiple processing units
- Includes an in-memory and replication engine
- Data is kept in-memory and replicated among active processing units
- Updates are sent asynchronously to the database
Virtualized Middleware
- Messaging Grid
- Manage input requests and session state
- Determine which active processing unit receive request and forwarding it
- Often implement using web server with load balancing (Nginx)
- Data Grid
- Important for interacting with the in-memory data grid
- Manage data replication between processing unit to ensure unit has the same data
- Replication typically asynchronous + fast
- Use data replication engine
- Processing Grid
- Optional component that manage orchestrated request processing when multiple processing unit process a single business request
- Deployment Manager
- Manage startup and shutdown processing units based on load conditions, also help monitoring response time and user loads to adjust the number of active units
Data Pump
- Send updated data asynchronously from a processing unit to data writer for eventual database update
- Usually implemented using messaging → guaranteed delivery + decoupling
- Typically dedicated to specific domains and subdomains
Data Writer
- Accept message from data pump → update database accordingly
- Can be implemented as services, applications, or data hubs
- Can be domain-based (handling all the update for a domain) or dedicated to specific data pump/processing unit
- Help decoupling processing unit from database structure
Data Reader
- Read data from database → Send to processing units via reverse data pump
- Only invoked when all processing unit instances crash or are redeployed, or to retrieve archived data not in the cache
- Can be domain-based too
Flow (EX: Online Auction System)
Online auction system has high + unpredictable load during bidding, let use space-based architecture Processing Units: Each unit will be dedicated to each auction. As load increase, the deployment manager start more processing units. Unused unit are shut down
- Bid are processed in the processing unit’s in-memory data grid. Updates (new highest bid) are replicated across relevant processing units
- Processing units responsible for the update sends to bidding data via a Data Pump to the Data Writer (Asynchronously Update)
- Data Writer update the database
- Because of asynchronous nature, it allow bidding data to be simultaneously sent (via other data pumps or event streams initiated by the processing unit) for other processing unit like bid history tracking, analytics, etc.
Characteristics
- Elasticity + Scalability + Performance + Fault Tolerance
Trade-offs
Advantages
- High Scalability & Elasticity: Effectively handles high and variable concurrent user loads
- High Performance: Achieved through in-memory data grids, removing database bottlenecks
- Cloud/On-Prem Flexibility: Can deploy processing units in the cloud while keeping databases on-prem
- Fault Tolerance (Cache): Replicated caches avoid single points of failure for cached data
Disadvantages
- Complexity: Difficult to implement and manage due to caching, data synchronization, eventual consistency, and potential data collisions
- Data Consistency: Relies on eventual consistency; data collisions are possible with replicated caches, although mitigatable. Distributed caches offer better consistency but lower performance/fault tolerance.
General Consideration
Data Collisions
- In this architecture, one processing unit update piece of data → copied change (replicated) to all other unit holding same data cache → This replication isn’t INSTANTANEOUS (small delay) (replication latency)
- Data Collisions when two or more processing unit try to update same piece of data at almost exact same time during replication latency
Cloud Versus On-Premises Implementations
- This architecture offer flexibility in deployment environment
- The entire system – processing units, virtualized middleware, data pumps/writers/readers, and the database – can be deployed entirely on-premises (in the company’s own data centers) or entirely in the cloud (like AWS or Azure).
- Hybrid deployment is real power, for example, pick advantage of each deployment service and apply to specific component (database + data writers/readers remain on-premises + processing units and the virtualized middleware on cloud to inherent elasticity and scalability)
Replicated vs Distributed Caching
- Caching is fundamental in this architecture, remove need for direct database access during most operations
-
Replicated Cache
- Each processing units hold a complete copy of relevant data cache in its own memory (in-memory data grid)
- One unit update its cache, change automatically copied (replicated) to all other units holding the same named cache (synchronize them) (usually asynchronous + quick)
- PROS: Extremely fast (Data is in local memory) + High fault tolerant (data exist in other copied)
- CONS: Can consume significant memory per processing unit + limit how many units can run on a machine + High update rate or large cache sizes can lead to replication latency cause data collision
-
Distributed Cache
- Cache data held centrally on one or more dedicated external cache servers
- Processing Units do not store the cache data locally → access it remotely from the central cache server
- PROS: Better data consistency ( no data collision ), Can handle very large volume without consuming memory on each processing unit
- CONS: Slower performance (remote access latency), Lower fault tolerance (central fail, can’t access data) (can mitigate with mirroring but add consistency issue, complexity)
Choosing
- Use replicated for smaller, relatively static data or when performance and fault tolerance are significant
- Use Distributed for very large datasets, frequent update or when processing units are constrained Application often use both types for different kinds of data
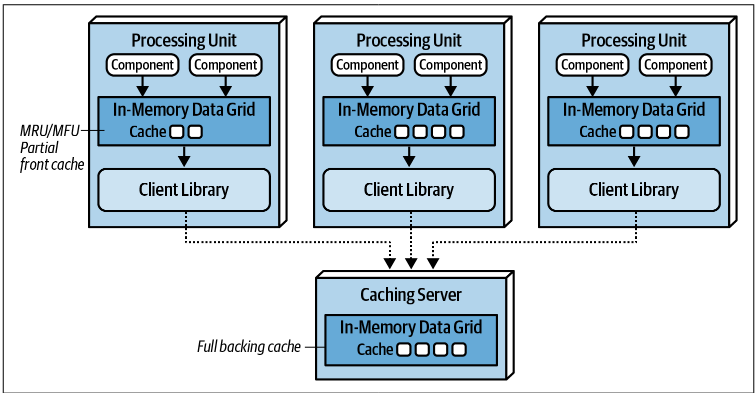
Near-Cache Considerations
- Near-cache is a hybrid caching model that tries to combine both replicated and distributed caching
- Involves two parts
- Full Backing Cache: Essentially a distributed cache, typically holding entire dataset on a central server
- Front Cache: Smaller, in-memory cache located within each processing unit. It hold a subset of the data from the full backing cache.
- When processing unit need data → check front cache → if cache miss then request data from full backing cache
- The front cache is kept synchronized with the full backing cache, but crucially, the front caches are not synchronized between the different processing units. This means Processing Unit A and Processing Unit B will likely have different subsets of data in their local front caches at any given time.
- Not recommended for space-based architecture precisely because the front caches aren’t synchronized with each other (Space-based architecture wants things to be consistently super-fast)
Orchestration-Driven Service-Oriented Architecture
This architecture style organizes services into a taxonomy based on technical capabilities and reuse goals
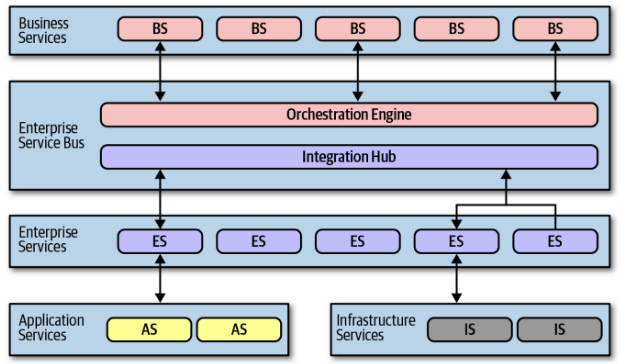
Components
Business Services
- Sit at the top layer, providing the main entry points for business operations
- These are typically abstract definitions (input, output, schema) without implementation code, often defined by business users
Enterprise Services
- Contain the fine-grained, shared implementation logic intended for reuse across the enterprise
- These are the atomic building blocks orchestrated to fulfill Business Services. The goal was to build a library of these reusable assets overtime
Application Services
- Represent one-off, specific services needed by a single application but not intended for wider reuse
- Usually owned by a single application team
Infrastructure Services
- Provide shared operational capabilities like monitoring, logging, authentication, and authorization
- Typically concrete implementations owned by a central infrastructure team
Orchestration Engine (ESB - Enterprise Service Bus)
- Central component that act as heart of architecture
- Handles message routing, transformation, and often manages distributed transactions declaratively
- Orchestrating the sequence of service calls necessary to fulfill a business process
Shared Database
- This architecture rely on single central relational database or small number of shared databases (often indirectly via the orchestration engine or specific data access layers within services)
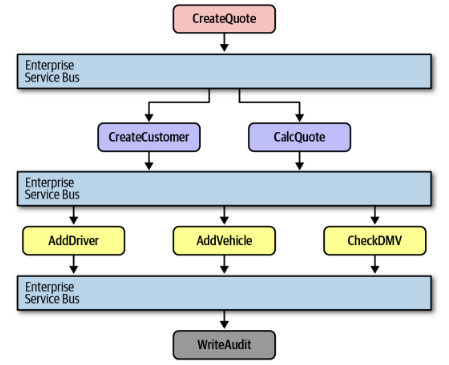
Flow (Consider a CreateQuote Business Service request)
- Request hit the orchestration engine (ESB)
- The engine, based on its define workflow for
CreateQuote, make a call to theCreateCustomerEnterprise Service - The engine then calls the
CalcQuoteEnterprise Service - These enterprise services might, in turn, need data or functionality from Application Services or Infrastructure Services. These calls also go back through the Orchestration Engine, which routes them appropriately
- The engine coordinates these calls, potentially managing transactions, and eventually returns the final result for the
CreateQuoterequest
Characteristic
- Reuse Focus: The primary goal was maximizing enterprise-level reuse of fine-grained services.
- Partitioning: Technically Partitioned. Services are grouped by technical function (business definition, enterprise implementation, application-specific, infrastructure) rather than business domain. Domain logic (like
CatalogCheckout) gets spread thinly across multiple layers and services. - Number of Quanta: One. Despite being distributed, the architecture behaves as a single quantum. This is due to the high coupling introduced by the shared database(s) and, more importantly, the central Orchestration Engine
- Coupling: Very high coupling between services due to the focus on reuse and the centralized orchestration
What
This architecture represents a historical approach driven by the desire for reuse in an era of expensive resources. Its primary lesson is the negative consequence of prioritizing reuse above all else, which leads to high coupling and hinders agility, testability, and deployability. It also highlights the challenges of central orchestration and technical partitioning for complex domain workflows.
Trade-offs
Advantages (mostly intended, often not fully realized, rarely achieve in practice):
- Potential for High Reuse: Theoretically aimed to reduce redundant code by axreusing fine-grained enterprise services.
- Centralized Control: Orchestration engine provided a single point to manage workflows and transactions (though complex in practice).
- Technical Separation: Clearly separated services based on technical roles.
Disadvantages (significant practical problems):
- High Coupling: The focus on reuse created tight dependencies between services, making changes difficult and risky.
- Low Agility: Hard to make changes quickly due to ripple effects and coordination needs.
- Poor Testability: Complex interactions and dependencies made testing hard.
- Difficult Deployability: Changes often required large, coordinated “big bang” deployments.
- Performance Issues: Central orchestration and numerous remote calls created significant overhead.
- Complexity: Became very complex to design, implement, manage, and debug, especially regarding distributed transactions.
- Domain Dilution: Business logic for a single workflow was scattered across many technical layers/services.
- Single Quantum: Limited ability for different parts of the system to have independent scalability or availability characteristics due to shared dependencies (database, engine).
- Organizational Bottlenecks: The team managing the central orchestration engine often became a bottleneck.