Introduction
This documentation explores the integration of Spark Streaming with web scraping using BeautifulSoup and Kafka. We’ll examine two approaches:
- Direct method: Using Spark Streaming with BeautifulSoup to scrape websites and process data in real-time
- Kafka-based method: Using Kafka as a middleware between web scrapers and Spark Streaming
Each approach has distinct advantages depending on scale, complexity, and requirements. By the end of this guide, you’ll understand how to implement both methods and which one best suits your use case.
Spark Streaming Overview
Apache Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data. Data can be ingested from many sources like Kafka, Flume, Kinesis, or TCP sockets, and can be processed using complex algorithms expressed with high-level functions like map, reduce, join, and window.
Streaming Models: DStream vs Structured Streaming
Spark offers two streaming models:
DStream (Discretized Stream)
- Basic abstraction in Spark Streaming
- Represents a continuous sequence of RDDs
- Based on micro-batch processing
- Original streaming API, more mature but less optimized
from pyspark.streaming import StreamingContext
# Create streaming context with 5-second batch interval
ssc = StreamingContext(sc, 5)Structured Streaming
- Newer, more powerful model
- Treats streaming data as an unbounded table
- Provides stronger guarantees and optimizations
- Better integration with Spark SQL
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("StructuredStreaming") \
.getOrCreate()
# Create streaming DataFrame
streaming_df = spark.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", "topic1") \
.load()Key Concepts
- Micro-batch processing: Streaming computations are executed as a series of small batch jobs
- Window operations: Process data within a sliding window of time
- Stateful processing: Maintain state across batches for complex analytics
- Checkpointing: Mechanism for fault tolerance and recovery
- Output modes: Complete, append, or update
Architecture

Spark Streaming divides the continuous stream of data into batches, which are then processed by the Spark engine to generate the final stream of results in batches.
Setting Up the Environment
Prerequisites
- Java 8 or later
- Python 3.6+
- Apache Spark 3.0+
- Apache Kafka 2.8+ (for Kafka integration)
- Python libraries: pyspark, beautifulsoup4, requests, kafka-python
Installation
-
Install Java:
sudo apt update sudo apt install openjdk-11-jdk -
Install Python and dependencies:
sudo apt install python3 python3-pip pip3 install pyspark beautifulsoup4 requests kafka-python -
Download and extract Spark:
wget https://downloads.apache.org/spark/spark-3.3.0/spark-3.3.0-bin-hadoop3.tgz tar -xzf spark-3.3.0-bin-hadoop3.tgz mv spark-3.3.0-bin-hadoop3 spark -
Set up environment variables:
export SPARK_HOME=/path/to/spark export PATH=$PATH:$SPARK_HOME/bin export PYSPARK_PYTHON=python3
Configuration
Create a base Spark configuration for streaming applications:
from pyspark.sql import SparkSession
def create_spark_session(app_name):
return SparkSession.builder \
.appName(app_name) \
.config("spark.streaming.stopGracefullyOnShutdown", "true") \
.config("spark.sql.shuffle.partitions", "8") \
.config("spark.executor.memory", "2g") \
.getOrCreate()Web Scraping with BeautifulSoup
BeautifulSoup is a Python library for parsing HTML and XML documents. It creates a parse tree that can be used to extract data easily.
BeautifulSoup Basics
import requests
from bs4 import BeautifulSoup
def scrape_page(url):
# Send HTTP request
response = requests.get(url)
# Check if request was successful
if response.status_code == 200:
# Parse HTML content
soup = BeautifulSoup(response.text, 'html.parser')
return soup
else:
print(f"Failed to fetch page: {response.status_code}")
return NoneScraping Example
Let’s create a simple scraper for a news website:
def extract_news_headlines(soup):
headlines = []
# Find all article titles (this selector will vary by website)
articles = soup.select('article h2')
for article in articles:
headlines.append({
'title': article.text.strip(),
'link': article.find('a')['href'] if article.find('a') else None
})
return headlines
# Example usage
url = "https://example-news-site.com"
soup = scrape_page(url)
if soup:
headlines = extract_news_headlines(soup)
for headline in headlines:
print(f"Title: {headline['title']}")
print(f"Link: {headline['link']}")
print("-" * 50)Integration with Spark
To use BeautifulSoup with Spark, we need to distribute the scraping operation across worker nodes:
def scrape_function(url):
import requests
from bs4 import BeautifulSoup
try:
response = requests.get(url, timeout=10)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# Extract data based on your requirements
title = soup.title.text if soup.title else "No title"
return (url, title, response.status_code)
else:
return (url, None, response.status_code)
except Exception as e:
return (url, None, str(e))
# Using with Spark
urls = ["https://www.example1.com", "https://www.example2.com"]
urls_rdd = spark.sparkContext.parallelize(urls)
results_rdd = urls_rdd.map(scrape_function)Method 1: Direct Web Scraping with Spark Streaming
In this approach, we use Spark Streaming to periodically trigger web scraping operations and process the results in real-time.
Implementation
Here’s a complete implementation using DStream API:
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
import requests
from bs4 import BeautifulSoup
import time
import json
# Create Spark context and streaming context
sc = SparkContext("local[2]", "WebScraperStream")
ssc = StreamingContext(sc, 60) # 60-second batch interval
# List of URLs to scrape
target_urls = [
"https://news.example.com/tech",
"https://news.example.com/business",
"https://news.example.com/science"
]
def scrape_url(url):
try:
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'}
response = requests.get(url, headers=headers, timeout=10)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
headlines = []
# Extract headlines (adjust selector for your target site)
for article in soup.select('article.news-item'):
title_elem = article.select_one('h2')
if title_elem:
title = title_elem.text.strip()
link = title_elem.find('a')['href'] if title_elem.find('a') else None
timestamp = int(time.time())
headlines.append({
'title': title,
'url': link,
'source': url,
'timestamp': timestamp
})
return headlines
else:
print(f"Failed to fetch {url}: {response.status_code}")
return []
except Exception as e:
print(f"Error scraping {url}: {str(e)}")
return []
def generate_rdd():
all_headlines = []
for url in target_urls:
headlines = scrape_url(url)
all_headlines.extend(headlines)
return sc.parallelize(all_headlines)
# Create a DStream that calls our scraping function on each interval
stream = ssc.socketTextStream("localhost", 9999) # Dummy source
scraper_stream = ssc.queueStream([], oneAtATime=False)
# Process the stream
def process_batch(time, rdd):
if not rdd.isEmpty():
# Count headlines by source
counts = rdd.map(lambda x: (x['source'], 1)).reduceByKey(lambda a, b: a + b)
# Print results
print(f"===== Batch at {time} =====")
for source, count in counts.collect():
print(f"{source}: {count} headlines")
# Save to file
rdd.map(lambda x: json.dumps(x)).saveAsTextFile(f"headlines/batch_{time.strftime('%Y%m%d_%H%M%S')}")
# Register a custom receiver
def get_next_rdd():
return generate_rdd()
# Schedule the scraping to happen every batch interval
scraper_stream = ssc.queueStream([], oneAtATime=False)
ssc.addStreamingListener(StreamingListener(scraper_stream, get_next_rdd))
# Process each batch
scraper_stream.foreachRDD(process_batch)
# Start the streaming context
ssc.start()
ssc.awaitTermination()You’ll need to implement a custom StreamingListener to add new RDDs to the queue:
from pyspark.streaming.listener import StreamingListener
class ScraperStreamingListener(StreamingListener):
def __init__(self, stream, generator_func):
self.stream = stream
self.generator_func = generator_func
def onBatchCompleted(self, batchCompleted):
# Generate new RDD for next batch
new_rdd = self.generator_func()
self.stream.queue.put(new_rdd)Example: News Headlines Scraper
Let’s implement a more structured example using Structured Streaming:
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
import requests
from bs4 import BeautifulSoup
import time
import json
import pandas as pd
# Create Spark Session
spark = SparkSession.builder \
.appName("StructuredNewsHeadlinesScraper") \
.config("spark.sql.shuffle.partitions", 4) \
.getOrCreate()
# Define schema for our data
schema = StructType([
StructField("title", StringType(), True),
StructField("url", StringType(), True),
StructField("source", StringType(), True),
StructField("category", StringType(), True),
StructField("timestamp", TimestampType(), True)
])
# URLs to scrape by category
urls_by_category = {
"technology": ["https://news.example.com/tech", "https://another-news.com/technology"],
"business": ["https://news.example.com/business", "https://another-news.com/economy"],
"science": ["https://news.example.com/science", "https://another-news.com/research"]
}
def scrape_headlines():
"""Scrape headlines from all target sites and return as DataFrame"""
all_headlines = []
for category, urls in urls_by_category.items():
for url in urls:
try:
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'}
response = requests.get(url, headers=headers, timeout=10)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# Extract headlines (adjust selector for your target site)
for article in soup.select('article.news-item'):
title_elem = article.select_one('h2')
if title_elem:
title = title_elem.text.strip()
link = title_elem.find('a')['href'] if title_elem.find('a') else None
current_time = time.time()
all_headlines.append({
'title': title,
'url': link,
'source': url,
'category': category,
'timestamp': pd.Timestamp.now()
})
except Exception as e:
print(f"Error scraping {url}: {str(e)}")
continue
# Create DataFrame from collected data
return spark.createDataFrame(pd.DataFrame(all_headlines), schema=schema)
# Function to create streaming DataFrame
def generate_streaming_df():
"""Generate a streaming DataFrame by repeatedly calling the scraper"""
def get_batch(batch_id):
return scrape_headlines()
return spark.readStream \
.format("rate") \
.option("rowsPerSecond", 1) \
.load() \
.withWatermark("timestamp", "2 minutes") \
.select(
expr("CAST(timestamp AS STRING) as timestamp"),
expr("CAST(value AS STRING) as value")
) \
.join(
get_batch(0),
expr("1 = 1"), # Always true join condition
"cross"
) \
.drop("timestamp", "value")
# Create streaming DataFrame
headlines_df = generate_streaming_df()
# Process the streaming data
query = headlines_df \
.writeStream \
.outputMode("append") \
.format("console") \
.option("truncate", False) \
.trigger(processingTime="1 minute") \
.start()
# Also save to files
query2 = headlines_df \
.writeStream \
.outputMode("append") \
.format("json") \
.option("path", "headlines_output") \
.option("checkpointLocation", "checkpoints/headlines") \
.trigger(processingTime="1 minute") \
.start()
query.awaitTermination()Note: The above example is conceptual. Structured Streaming doesn’t directly support this pattern of data generation, so in practice you might need to use an external trigger system or a custom source.
Performance Considerations
When directly scraping websites with Spark Streaming:
- Rate limiting: Be respectful of websites by limiting request frequency
- Parallelism: Balance parallelism with respect for the target website
- Error handling: Network failures and HTML changes are common
- Resource usage: Web scraping can be resource-intensive
- Legal considerations: Ensure compliance with target website’s Terms of Service
Method 2: Kafka Integration
Using Kafka as a middleware between web scraping and Spark Streaming decouples the data collection and processing components.
Kafka Architecture
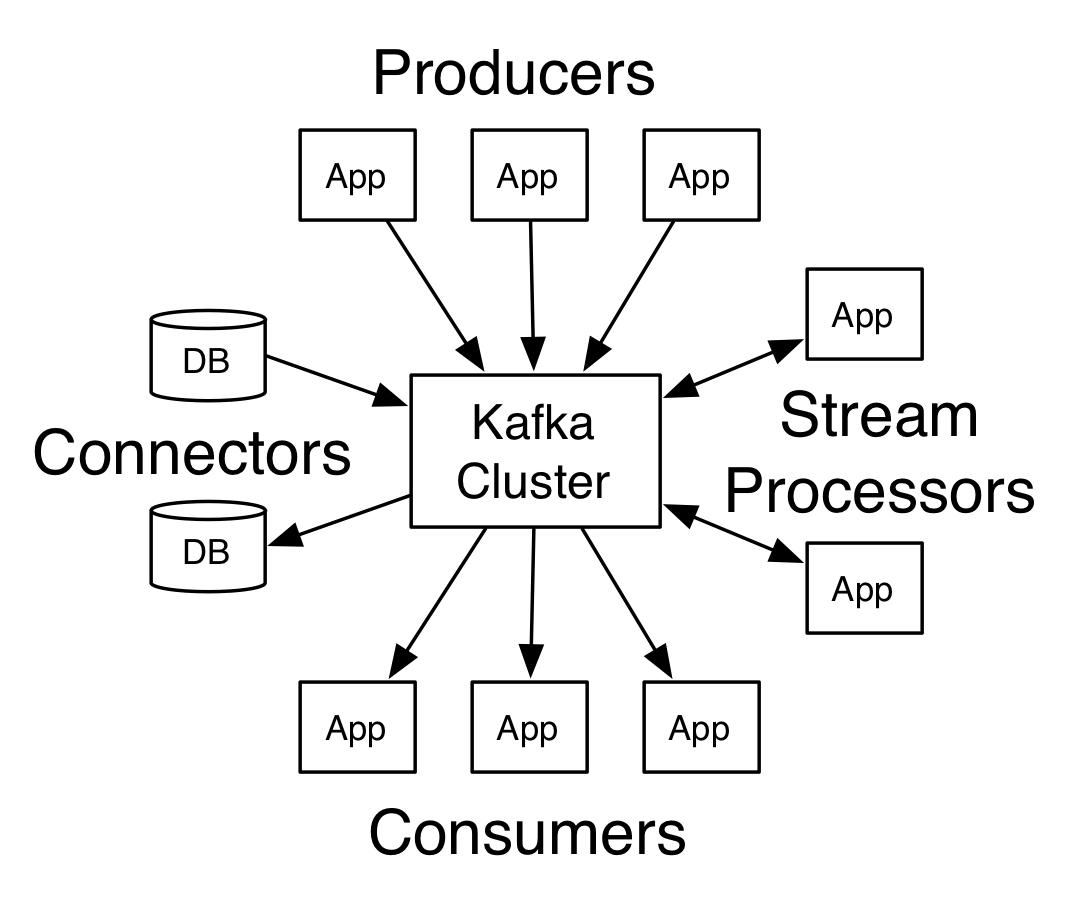
Kafka functions as a distributed event streaming platform with:
- Topics: Categories/feeds of messages
- Producers: Applications that publish data to topics
- Consumers: Applications that subscribe to topics
- Brokers: Kafka servers that store data
Setting Up Kafka
- Download and extract Kafka:
wget https://downloads.apache.org/kafka/3.2.1/kafka_2.13-3.2.1.tgz
tar -xzf kafka_2.13-3.2.1.tgz
cd kafka_2.13-3.2.1- Start Zookeeper (Kafka dependency):
bin/zookeeper-server-start.sh config/zookeeper.properties- Start Kafka server:
bin/kafka-server-start.sh config/server.properties- Create a topic:
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic web-scraper-dataProducer Implementation
Here’s a Python producer that scrapes websites and sends data to Kafka:
import requests
from bs4 import BeautifulSoup
import json
import time
from kafka import KafkaProducer
import schedule
# Configure Kafka producer
producer = KafkaProducer(
bootstrap_servers=['localhost:9092'],
value_serializer=lambda x: json.dumps(x).encode('utf-8')
)
# URLs to scrape
target_urls = {
"tech": "https://news.example.com/tech",
"business": "https://news.example.com/business",
"science": "https://news.example.com/science"
}
def scrape_and_send():
"""Scrape all target URLs and send data to Kafka"""
print(f"Starting scraping job at {time.strftime('%Y-%m-%d %H:%M:%S')}")
for category, url in target_urls.items():
try:
# Set headers to mimic a browser
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
# Send request
response = requests.get(url, headers=headers, timeout=10)
if response.status_code == 200:
# Parse HTML
soup = BeautifulSoup(response.text, 'html.parser')
# Extract headlines (adjust for actual site structure)
articles = soup.select('article.news-item')
for idx, article in enumerate(articles):
try:
# Extract article data
title_elem = article.select_one('h2')
if not title_elem:
continue
title = title_elem.text.strip()
link = title_elem.find('a')['href'] if title_elem.find('a') else None
# Create data object
data = {
'title': title,
'url': link,
'source_url': url,
'category': category,
'timestamp': time.time(),
'scrape_time': time.strftime('%Y-%m-%d %H:%M:%S')
}
# Send to Kafka
producer.send('web-scraper-data', value=data)
print(f"Sent: {title[:30]}...")
except Exception as e:
print(f"Error processing article {idx} from {url}: {str(e)}")
print(f"Processed {len(articles)} articles from {category}")
else:
print(f"Failed to fetch {url}: HTTP {response.status_code}")
except Exception as e:
print(f"Error fetching {url}: {str(e)}")
# Ensure all messages are sent
producer.flush()
print(f"Completed scraping job at {time.strftime('%Y-%m-%d %H:%M:%S')}")
# Run once immediately
scrape_and_send()
# Schedule to run every 30 minutes
schedule.every(30).minutes.do(scrape_and_send)
# Keep the script running
while True:
schedule.run_pending()
time.sleep(1)Consumer with Spark Streaming
Now let’s implement a Spark Streaming application that consumes and processes this data:
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
# Create Spark Session
spark = SparkSession.builder \
.appName("KafkaNewsHeadlineProcessor") \
.config("spark.streaming.stopGracefullyOnShutdown", "true") \
.getOrCreate()
# Define schema for JSON data
schema = StructType([
StructField("title", StringType(), True),
StructField("url", StringType(), True),
StructField("source_url", StringType(), True),
StructField("category", StringType(), True),
StructField("timestamp", DoubleType(), True),
StructField("scrape_time", StringType(), True)
])
# Read from Kafka
kafka_df = spark.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", "web-scraper-data") \
.option("startingOffsets", "latest") \
.load()
# Extract and parse the JSON value
value_df = kafka_df.select(
from_json(col("value").cast("string"), schema).alias("value")
)
# Extract fields from the nested structure
expanded_df = value_df.select("value.*")
# Add processing timestamp
processed_df = expanded_df.withColumn(
"processing_time", current_timestamp()
).withColumn(
"scrape_timestamp", to_timestamp(col("timestamp"))
)
# Calculate time lag between scraping and processing
final_df = processed_df.withColumn(
"processing_lag_sec",
unix_timestamp(col("processing_time")) - col("timestamp")
)
# Process the data with various operations
# 1. Count headlines by category
category_counts = final_df \
.groupBy(
window(col("scrape_timestamp"), "5 minutes"),
col("category")
) \
.count()
# Output to console for debugging
query1 = category_counts \
.writeStream \
.outputMode("complete") \
.format("console") \
.option("truncate", False) \
.trigger(processingTime="1 minute") \
.start()
# 2. Save raw data to Parquet files
query2 = final_df \
.writeStream \
.outputMode("append") \
.format("parquet") \
.option("path", "headlines_data") \
.option("checkpointLocation", "checkpoints/headlines_raw") \
.trigger(processingTime="1 minute") \
.start()
# 3. Text analysis - extract keywords
# Add text processing with explode for keywords
text_df = final_df.select(
col("title"),
col("category"),
col("scrape_timestamp"),
explode(
split(
lower(regexp_replace(col("title"), "[^a-zA-Z\\s]", " ")), "\\s+"
)
).alias("word")
).filter(length(col("word")) > 3) # Filter out short words
# Count word frequency
word_counts = text_df \
.groupBy(
window(col("scrape_timestamp"), "30 minutes"),
col("category"),
col("word")
) \
.count() \
.orderBy(col("window"), col("count").desc())
# Output word frequencies
query3 = word_counts \
.writeStream \
.outputMode("complete") \
.format("memory") \
.queryName("word_frequencies") \
.trigger(processingTime="1 minute") \
.start()
# Wait for termination
spark.streams.awaitAnyTermination()Example: Real-time Product Monitor
Here’s a complete example that monitors product prices across e-commerce websites:
# Producer: Scraper that sends data to Kafka
import requests
from bs4 import BeautifulSoup
import json
import time
from kafka import KafkaProducer
import schedule
import random
# Products to monitor
products = [
{
"name": "Smartphone X",
"urls": {
"store1": "https://store1.example.com/products/smartphone-x",
"store2": "https://store2.example.com/electronics/smartphone-x",
"store3": "https://store3.example.com/smartphone-x-latest"
}
},
{
"name": "Laptop Pro",
"urls": {
"store1": "https://store1.example.com/products/laptop-pro",
"store2": "https://store2.example.com/computers/laptop-pro",
"store4": "https://store4.example.com/laptop-pro-2023"
}
}
]
# Initialize Kafka producer
producer = KafkaProducer(
bootstrap_servers=['localhost:9092'],
value_serializer=lambda x: json.dumps(x).encode('utf-8')
)
def extract_price(soup, store):
"""Extract price based on store-specific selectors"""
selectors = {
"store1": "span.price",
"store2": "div.product-price",
"store3": "p.current-price",
"store4": "div.price-container span.amount"
}
# For demonstration, we'll simulate finding prices
# In a real scenario, you'd use the actual selectors to find prices
try:
# Simulated price extraction for demo purposes
# In reality: price_elem = soup.select_one(selectors[store])
# Simulate price with random variation for demo
base_prices = {
"Smartphone X": 899.99,
"Laptop Pro": 1299.99
}
product_name = next((p["name"] for p in products if store in p["urls"]), None)
if product_name and product_name in base_prices:
# Add small random variation to simulate price changes
variation = random.uniform(-50, 50)
price = base_prices[product_name] + variation
return round(price, 2)
return None
except Exception:
return None
def scrape_product_prices():
"""Scrape product prices and send to Kafka"""
print(f"Starting price scraping at {time.strftime('%Y-%m-%d %H:%M:%S')}")
for product in products:
product_name = product["name"]
for store, url in product["urls"].items():
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
# In a real implementation, you would uncomment this
# response = requests.get(url, headers=headers, timeout=10)
# if response.status_code == 200:
# soup = BeautifulSoup(response.text, 'html.parser')
# else:
# print(f"Failed to fetch {url}: HTTP {response.status_code}")
# continue
# For demo, we'll simulate a successful request
# Mock soup object for demonstration
soup = BeautifulSoup("<html></html>", 'html.parser')
# Extract price
price = extract_price(soup, store)
if price:
# Create data object
data = {
'product_name': product_name,
'store': store,
'price': price,
'currency': 'USD',
'url': url,
'timestamp': time.time(),
'scrape_time': time.strftime('%Y-%m-%d %H:%M:%S')
}
# Send to Kafka
producer.send('product-prices', value=data)
print(f"Sent: {product_name} price from {store}: ${price}")
else:
print(f"Could not extract price for {product_name} from {store}")
except Exception as e:
print(f"Error processing {url}: {str(e)}")
# Ensure all messages are sent
producer.flush()
print(f"Completed price scraping at {time.strftime('%Y-%m-%d %H:%M:%S')}")
# Run once immediately
scrape_product_prices()
# Schedule to run every 15 minutes
schedule.every(15).minutes.do(scrape_product_prices)
# Keep the script running
while True:
schedule.run_pending()
time.sleep(1)Spark Streaming consumer for the price data:
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
from pyspark.sql.window import Window
# Create Spark Session
spark = SparkSession.builder \
.appName("ProductPriceMonitor") \
.config("spark.streaming.stopGracefullyOnShutdown", "true") \
.getOrCreate()
# Define schema for JSON data
schema = StructType([
StructField("product_name", StringType(), True),
StructField("store", StringType(), True),
StructField("price", DoubleType(), True),
StructField("currency", StringType(), True),
StructField("url", StringType(), True),
StructField("timestamp", DoubleType(), True), # Unix timestamp (seconds)
StructField("scrape_time", StringType(), True) # String representation
])
# Read from Kafka
kafka_df = spark.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", "product-prices") \
.option("startingOffsets", "latest") \
.load()
# Extract and parse the JSON value
value_df = kafka_df.select(
from_json(col("value").cast("string"), schema).alias("value")
)
# Extract fields from the nested structure and cast timestamp
prices_df = value_df.select("value.*") \
.withColumn("event_timestamp", to_timestamp(col("timestamp"))) # Convert epoch seconds to TimestampType
# Add processing timestamp
processed_prices_df = prices_df.withColumn(
"processing_time", current_timestamp()
)
# Define window for analysis (e.g., 1 hour window, sliding every 15 minutes)
price_window = window(col("event_timestamp"), "1 hour", "15 minutes")
# Analyze price trends per product and store within the window
price_analysis = processed_prices_df \
.groupBy(
price_window,
col("product_name"),
col("store")
) \
.agg(
count("*").alias("price_updates"),
min("price").alias("min_price"),
max("price").alias("max_price"),
avg("price").alias("avg_price")
) \
.orderBy("window")
# Detect significant price drops (simple example: current price is 10% less than max price in the window)
# Note: This requires stateful processing or joining with historical data for a robust solution
# For a simple example using just the current batch, we can compare current price to a running aggregate if we add state
# Using a simple approach for demonstration within the batch:
# Keep track of the latest price seen for each product/store combination
latest_prices = processed_prices_df \
.dropDuplicates(["product_name", "store"]) # Keep only the latest record in this microbatch for simplicity
# Output to console (for demonstration)
query1 = price_analysis \
.writeStream \
.outputMode("update") # Use 'update' mode for aggregates with windowing
.format("console") \
.option("truncate", False) \
.trigger(processingTime="1 minute") \
.start()
# Output latest prices to memory table for querying
query2 = latest_prices \
.writeStream \
.outputMode("complete") \
.format("memory") \
.queryName("latest_product_prices") \
.trigger(processingTime="1 minute") \
.start()
# You could query the memory table from another SparkSession or a SQL client
# For example: spark.sql("SELECT * FROM latest_product_prices").show()
# You might also want to save the raw data to a persistent store
query3 = processed_prices_df \
.writeStream \
.outputMode("append") \
.format("parquet") \
.option("path", "product_prices_raw") \
.option("checkpointLocation", "checkpoints/product_prices_raw") \
.trigger(processingTime="5 minutes") \
.start()
# Wait for the termination of any of the queries
spark.streams.awaitAnyTermination()Comparison: Direct Scraping vs Kafka
Choosing between direct web scraping with Spark Streaming and using Kafka as an intermediary depends heavily on the requirements of your application.
Scalability
- Direct Scraping:
- Scaling involves increasing Spark cluster resources (executors).
- The scraping load is directly tied to the Spark Streaming batch interval and the number of URLs.
- Can be difficult to manage scraping load balancing across workers while respecting target website rate limits.
- Adding new URLs or sources might require code changes and redeployments of the Spark job.
- Kafka Integration:
- Highly scalable. Scraping (producers) can scale independently of processing (consumers).
- Adding more scraper instances (producers) increases data ingestion rate into Kafka.
- Adding more Spark consumer instances increases processing throughput.
- Kafka itself is designed for distributed scaling and can handle high volumes of data.
Fault Tolerance
- Direct Scraping:
- If a Spark worker fails during scraping, the data for that batch might be lost or need re-processing depending on Spark’s fault tolerance settings and the receiver type (reliable receivers are needed, but custom receivers like the queueStream method used earlier need careful implementation).
- Transient network issues during scraping attempts within a batch can lead to data loss or incomplete batches.
- Kafka Integration:
- Kafka provides built-in fault tolerance by replicating data across brokers.
- Data is persisted in Kafka topics, acting as a buffer. If a Spark consumer fails, it can restart and read from where it left off (managed by consumer groups and offsets).
- Scraper failures don’t directly impact the Spark processing stream, as long as other scrapers continue sending data or the failed scraper can restart.
Decoupling and Flexibility
- Direct Scraping:
- Tightly coupled architecture. The scraping logic is embedded within the Spark Streaming job.
- Changes to scraping logic or target websites require modifying and restarting the Spark job.
- Difficult to have multiple applications consume the scraped data simultaneously.
- Kafka Integration:
- Decoupled architecture. Scrapers (producers) are separate from Spark consumers.
- Scraping logic can be updated and deployed independently of the Spark processing job.
- Kafka serves as a central data bus. Multiple consumers (Spark, other applications, databases) can subscribe to the same data stream independently.
- Allows for easier integration with other systems or workflows.
Complexity
- Direct Scraping:
- Simpler setup if you only need basic real-time processing of scraped data.
- Fewer components to manage.
- Kafka Integration:
- Adds operational complexity by introducing Kafka as another component to set up, manage, and monitor.
- Requires managing Kafka topics, brokers, producers, and consumer configurations.
Latency
- Direct Scraping:
- Potentially lower end-to-end latency if the scraping and processing can happen quickly within a microbatch.
- Latency is primarily determined by the Spark Streaming batch interval and the time taken to scrape the websites.
- Kafka Integration:
- Adds slight latency due to data passing through Kafka.
- Latency is determined by the scraping frequency, Kafka buffering, and the Spark Streaming batch interval. Often acceptable for many real-time use cases.
Use Case Recommendations
- Choose Direct Scraping when:
- The volume of data is relatively low or moderate.
- The number of target websites is small and stable.
- You need minimal architectural components and simplicity is a priority.
- The scraping frequency is low and doesn’t heavily impact the target sites.
- Fault tolerance requirements are less stringent.
- Choose Kafka Integration when:
- You need to scrape a large number of websites or handle a high volume of data.
- You require high scalability and the ability to independently scale scraping and processing.
- Robust fault tolerance and data durability are critical.
- You need to decouple data collection from processing logic.
- Multiple applications need access to the scraped data stream.
- You anticipate frequent changes to scraping targets or logic without impacting the processing pipeline.
Advanced Topics
Checkpointing
Checkpointing is crucial for making Spark Streaming applications fault-tolerant. It periodically saves the state of the streaming application (like offsets, configurations, and in-progress data) to a reliable storage system (HDFS, S3, etc.). This allows the application to recover from failures and continue processing data without losing state.
-
Structured Streaming: Checkpointing is configured directly in the
writeStreamoperation.Python
query = streaming_df \ .writeStream \ .option("checkpointLocation", "/path/to/checkpoint/directory") \ .start() -
DStream: Checkpointing is configured on the
StreamingContext.Python
ssc.checkpoint("/path/to/checkpoint/directory")
Choosing an appropriate checkpointing interval is important. Too frequent can add overhead; too infrequent can lead to more data re-processing on recovery.
Window Operations
Window operations allow computations over a sliding window of data based on event time or processing time. This is essential for analyzing data trends over time periods.
-
Structured Streaming: Uses
windowfunction ingroupByandaggwith an event time column and watermarking to handle late data.Python
df.groupBy(window(df.timestamp, "10 minutes", "5 minutes")).count()window(eventTime, windowDuration, slideDuration) -
DStream: Provides windowing functions like
window,countByWindow,reduceByWindow, etc.Python
dstream.window(windowDuration, slideDuration)
Handling Backpressure
Backpressure occurs when your Spark Streaming application receives data faster than it can process it. This can lead to increased latency, resource exhaustion, and potential job failures.
-
Spark automatically handles backpressure in newer versions by monitoring the processing rate and adjusting the ingestion rate dynamically.
-
You can manually enable or configure backpressure:
# For Structured Streaming (auto-enabled by default)
spark.conf.set("spark.streaming.backpressure.enabled", "true")
# For DStream (needs manual enablement)
spark.sparkContext.getConf().set("spark.streaming.backpressure.enabled", "true")-
Tuning options like
spark.streaming.backpressure.maxRatePerPartitioncan help control the maximum ingest rate. -
Ensuring sufficient processing capacity (executors, cores, memory) is also key to handling backpressure.
Monitoring and Debugging
Monitoring Spark Streaming applications is vital for performance tuning and identifying issues.
- Spark Web UI: Provides a comprehensive view of jobs, stages, tasks, and streaming batches. You can see batch completion times, input sizes, processing times, and potential bottlenecks.
- Streaming Tab: The Spark UI includes a dedicated “Streaming” tab showing statistics for each stream, including batch delays, processing times, and throughput.
- Ganglia or Prometheus/Grafana: For more advanced cluster-level monitoring and historical trends.
- Logging: Configure logging levels to get detailed information about application execution.
- Metrics: Spark emits various metrics that can be collected and analyzed.
- Debugging: Use breakpoints (if running locally), inspect logs, and analyze the Spark UI to understand the execution flow and identify errors.
Best Practices
- Respect Website Terms of Service: Always check a website’s
robots.txtfile and Terms of Service before scraping. Avoid aggressive scraping that could overload their servers. - Use User-Agents and Delays: Mimic normal browser behavior by setting appropriate
User-Agentheaders and introducing delays between requests. - Implement Robust Error Handling: Be prepared for network errors, connection timeouts, and changes in website structure. Use
try...exceptblocks. - Handle HTML Parsing Robustly: Website HTML structures can change. Write resilient parsing code that anticipates missing elements or different structures.
- Scale Independently (with Kafka): Leverage the decoupling provided by Kafka to scale your scraping processes and Spark processing jobs independently based on load.
- Monitor and Tune: Continuously monitor your Spark Streaming job and Kafka cluster. Tune configurations like batch intervals, parallelism, and resource allocation for optimal performance.
- Checkpoint Regularly: Enable checkpointing to ensure fault tolerance and prevent data loss. Choose a reliable storage system for checkpoints.
- Consider Rate Limiting: Implement rate limiting in your scraping logic (producers) to avoid overwhelming target websites.
- Use Structured Streaming: Where possible, prefer Structured Streaming over DStreams due to its richer API, better performance, and easier integration with Spark SQL.
- Manage State Carefully: If your application requires stateful operations (e.g., tracking price changes over time), understand how state is managed in Spark Streaming and use checkpointing effectively.
References
- Apache Spark Documentation: https://spark.apache.org/docs/latest/
- Spark Structured Streaming Programming Guide: https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html12
- Spark Streaming Programming Guide (DStream): https://spark.apache.org/docs/latest/streaming-programming-guide.html3
- Beautiful Soup Documentation: https://www.crummy.com/software/BeautifulSoup/bs4/doc/4
- Apache Kafka Documentation: https://kafka.apache.org/documentation/
- spark-streaming-kafka-0-10-integration: https://spark.apache.org/docs/latest/structured-streaming-kafka-integration.html5 (for Structured Streaming)
- spark-streaming-kafka-0-10-integration: https://spark.apache.org/docs/latest/streaming-kafka-0-10-integration.html6 (for DStreams)
- Requests: HTTP for Humans™: https://docs.python-requests.org/en/latest/
- Schedule: Python job scheduling for humans: https://schedule.readthedocs.io/en/stable/